Yanny vs. Laurel
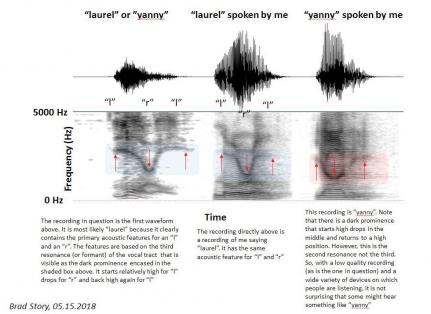
We decided to opine on the Laurel vs. Yanny phenomenon. The best explanation of the acoustical principles giving rise to this phenomenon came originally from Dr. Monson’s doctoral advisor at the University of Arizona, Dr. Brad Story. The image below was created by Dr. Story, taken from an NPR news story.
Necessary background knowledge: Human speech is made possible by a dynamic vocal tract, formed by the motile anatomy of the mouth and throat. The airspace (or “tube”) formed by the vocal tract has natural resonance frequencies related to the size and shape of the tube. These natural resonances, called formants, provide the auditory system with clues as to the size and shape of the tube. When you speak, every time you move your jaw, tongue, pharynx, etc. you change these resonance frequencies, and that change in resonances is perceived as a change in vowel or, in some cases, consonant (like ‘L’ vs. ‘R’). There are several formants (i.e., resonances) that come into play in vowel and consonant perception, but most of speech research has been focussed on the first three formants, aptly named F1, F2, and F3. The focus on these three formants is likely because, of the speech formants that have been studied, these appear to be the most dynamic, thereby conveying the most information about the tube.
So what gives with Yanny and Laurel? If you examine the second panel in the figure below (a spectrogram of Dr. Story saying “laurel”), what you see is a dark band representing F3 (highlighted with the blue box) that starts high, moves downward, and then moves back up (as indicated by the arrows). This is the change expected in F3 when you move your tongue from ‘L’ to ‘R’ back to ‘L’. In the third panel (Dr. Story saying “yanny”), we see a similar change, this time in F2 (highlighted with the red box). This is the change expected in F2 when you move your jaw from “ee” to “ae” (as in "bad") back to “ee.” Now, if you examine the first panel (the actual recording going around), you can see the dark band moving down and back up, but the signal is degraded enough to confuse the brain as to whether it is F2 or F3. This appears to be because F1 and/or F2 are getting a little lost or even combined with each other. We know by now that the original recording was “laurel.” If you hear “yanny,” it is likely because you are unable to reliably distinguish the real F1 and F2, so your brain is convinced that the F1/F2 combo is just F1, and that the change in F3 is actually a change in F2. The task of tracking F1 and F2 is made difficult by the degraded recording, and is further complicated by playing the audio over poor-quality loudspeakers found in some computers, phones, headphones, etc. This process may also be introducing other acoustic features that reinforce the perception of one word over the other.
Although the acoustical principles giving rise to this ambiguity are fascinating, what might be more intriguing is the following question: What influences one brain to perceive “yanny” and another to perceive “laurel” when faced with this ambiguous stimulus? Some have suggested that high-frequency hearing loss is one factor, arguing that the high frequencies in the stimulus are more similar to those that would be generated when saying “yanny” (read more about high frequencies in speech here). Thus, with degraded access to these higher frequencies, those with high-frequency hearing loss or presbycusis should be more likely to hear “laurel.” Others have suggested priming is key. If you are told that what you will hear is “laurel” or “yanny,” you are more likely to hear that word. Hearing loss and priming probably both play a role, but latching on to these narrow explanations prevents one from seeing the richer, more complete explanation: individualized anatomy combined with individualized life experience determine what we perceive.
Anatomy
Some individuals have anatomical features that bias the brain toward perceiving either “laurel” or "yanny." These features could include damaged anatomy (leading to hearing loss), or could have nothing to do with hearing loss. For example, some people will have ear anatomy that more readily emphasizes high frequencies, or low frequencies, or some other acoustic feature that biases the brain toward one word or the other.
Experience
Everyone has individual life experience that has taught his or her brain how to interpret any given stimulus (auditory or otherwise) to successfully navigate this crazy world. Although some experiences are common to nearly all humans, because each of our lives is different, we each have learned to perceive the world in a slightly (or substantially) different way. Why does one person hear “laurel”? Because that person’s life experience has taught the brain that hearing “laurel” is necessary for success. Why does another hear “yanny”? Because that individual’s life experience dictates that hearing “yanny” will lead to success.
An Example
These principles can be demonstrated by a simple scenario that occurred in our lab. Two lab members listened to the recording over an iMac internal loudspeaker and both heard “yanny.” They each then took turns listening to the recording over studio-grade headphones (Sennheiser HD 280 Pro) and both heard “laurel.” Following this brief 10-second experience, they listened again over the iMac speaker and one now heard “laurel” while the other continued to hear “yanny.”
Consider what took place here. Whatever differences in their anatomy (one was female, one male; one had hearing loss, one didn’t; etc.), whatever differences in their life experiences (one was younger, one older; one grew up in the West, one grew up in the Midwest; etc.), the anatomy and life experience they each brought to the table dictated that their brains should perceive “yanny” initially. The 10-second experience of perceiving “laurel” over the headphones was powerful enough to override any of those prior factors for one lab member. This lab member now couldn’t get back to perceiving “yanny” over the iMac. However, that same experience was not potent enough to counteract the lifetime of experiences and anatomical biases for the other lab member. This lab member still couldn’t get “laurel” out of the iMac, despite best efforts.
Priming? Okay. Hearing loss? Maybe. Degraded acoustics? Sure. But the real lesson is this: individualized anatomy combined with individualized life experience determine what we perceive. Our conclusion? Yes, what you hear is not what I hear. We will likely be unable to ever truly experience what another human experiences, even for short and simple experiences such as hearing the word “laurel” or seeing the color blue. You can decide to be disheartened by that, or to be fascinated by it. We recommend that latter. Such fascination can lead to a lifetime of discovery and effort to try to understand how each unique individual operates, even if we can’t truly experience what that individual experiences. That effort and increased understanding can then promote finding more common ground, not less; more unity, and less division; more empathy, and less criticism. Hopefully everyone can perceive that as a good thing.